Deep Recurrent Nets character generation demo
This demo shows usage of Robert Munafo's
version of Andrej
Karpathy's recurrentjs library that allows you to train deep
Recurrent Neural Networks (RNN) and Long Short-Term Memory Networks
(LSTM) in Javascript. But the core of the library is more general and
allows you to set up arbitrary expression graphs that support fully
automatic backpropagation.
In this demo we take a dataset of sentences as input and learn to memorize the sentences character by character. That is, the RNN/LSTM takes a character, its context from previous time steps (as mediated by the hidden layers) and predicts the next character in the sequence. Here is an example:
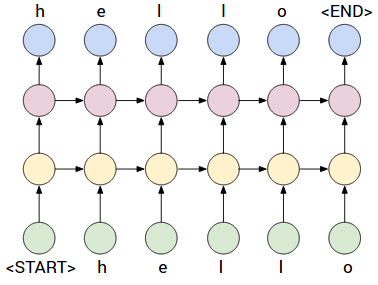 In the example image above that depicts a deep RNN, every character
has an associated "letter vector" that we will train with
backpropagation. These letter vectors are combined through a
(learnable) Matrix-vector multiply transformation into the first
hidden layer representation (yellow), then into second hidden layer
representation (purple), and finally into the output space (blue). The
output space has dimensionality equal to the number of characters in
the dataset and every dimension provides the probability of the next
character in the sequence. The network is therefore trained to always
predict the next character (using Softmax + cross-entropy loss on all
letters). The quantity we track during training is called
the perplexity, which measures how surprised the network is to
see the next character in a sequence. For example, if perplexity is
4.0 then it's as if the network was guessing uniformly at random from
4 possible characters for next letter (i.e. lowest it can be is 1). At
test time, the prediction is currently done iteratively character by
character in a greedy fashion, but I might eventually implemented more
sophisticated methods (e.g. beam search).
In the example image above that depicts a deep RNN, every character
has an associated "letter vector" that we will train with
backpropagation. These letter vectors are combined through a
(learnable) Matrix-vector multiply transformation into the first
hidden layer representation (yellow), then into second hidden layer
representation (purple), and finally into the output space (blue). The
output space has dimensionality equal to the number of characters in
the dataset and every dimension provides the probability of the next
character in the sequence. The network is therefore trained to always
predict the next character (using Softmax + cross-entropy loss on all
letters). The quantity we track during training is called
the perplexity, which measures how surprised the network is to
see the next character in a sequence. For example, if perplexity is
4.0 then it's as if the network was guessing uniformly at random from
4 possible characters for next letter (i.e. lowest it can be is 1). At
test time, the prediction is currently done iteratively character by
character in a greedy fashion, but I might eventually implemented more
sophisticated methods (e.g. beam search).
The demo is pre-filled with sentences from Paul Graham's essays, in an attempt to encode Paul Graham's knowledge into the weights of the Recurrent Networks. The long-term goal of the project then is to generate startup wisdom at will. Feel free to train on whatever data you wish, and to experiment with the parameters. If you want more impressive models you have to increase the sizes of hidden layers, and maybe slightly the letter vectors. However, this will take longer to train.
For suggestions/bugs ping me at @mrob_27.
In this demo we take a dataset of sentences as input and learn to memorize the sentences character by character. That is, the RNN/LSTM takes a character, its context from previous time steps (as mediated by the hidden layers) and predicts the next character in the sequence. Here is an example:
The demo is pre-filled with sentences from Paul Graham's essays, in an attempt to encode Paul Graham's knowledge into the weights of the Recurrent Networks. The long-term goal of the project then is to generate startup wisdom at will. Feel free to train on whatever data you wish, and to experiment with the parameters. If you want more impressive models you have to increase the sizes of hidden layers, and maybe slightly the letter vectors. However, this will take longer to train.
For suggestions/bugs ping me at @mrob_27.
Input sentences:
Options/Controls:
protip: if you see "perplexity: Infinity" try lowering the initial learning rate
Training stats:
Model samples:
Greedy argmax prediction:
I/O save/load model JSON
Pretrained model:
You can also choose to load these example pretrained models to see what the predictions look like in later stages. "trained Paul Graham" is an LSTM with one layer of 100 units, trained for ~10 hours on the Paul Graham sentences. After clicking the button, you should see the perplexity plummet to about 3.0, and the predictions become better. The page will also become less responsive, because it takes more time to perform each step with a 100x100 matrix operation, as compared to the default of two 20x20 operations. The "Shakespeare" model is much larger and should be attempted only if your browser is very fast when running the Graham example.
To save the current model, hit "save model", then copy the JSON
format text from the textarea box below and save in a local
textfile. To load a previously-saved model, paste JSON text into
the textarea box and hit "load model".